자료구조에 대한 기본적인 설명

단순 구조, 순차, 연결 리스트, 파일 구조를 제외하여 설명할 예정이다.
1. 스택 Stack
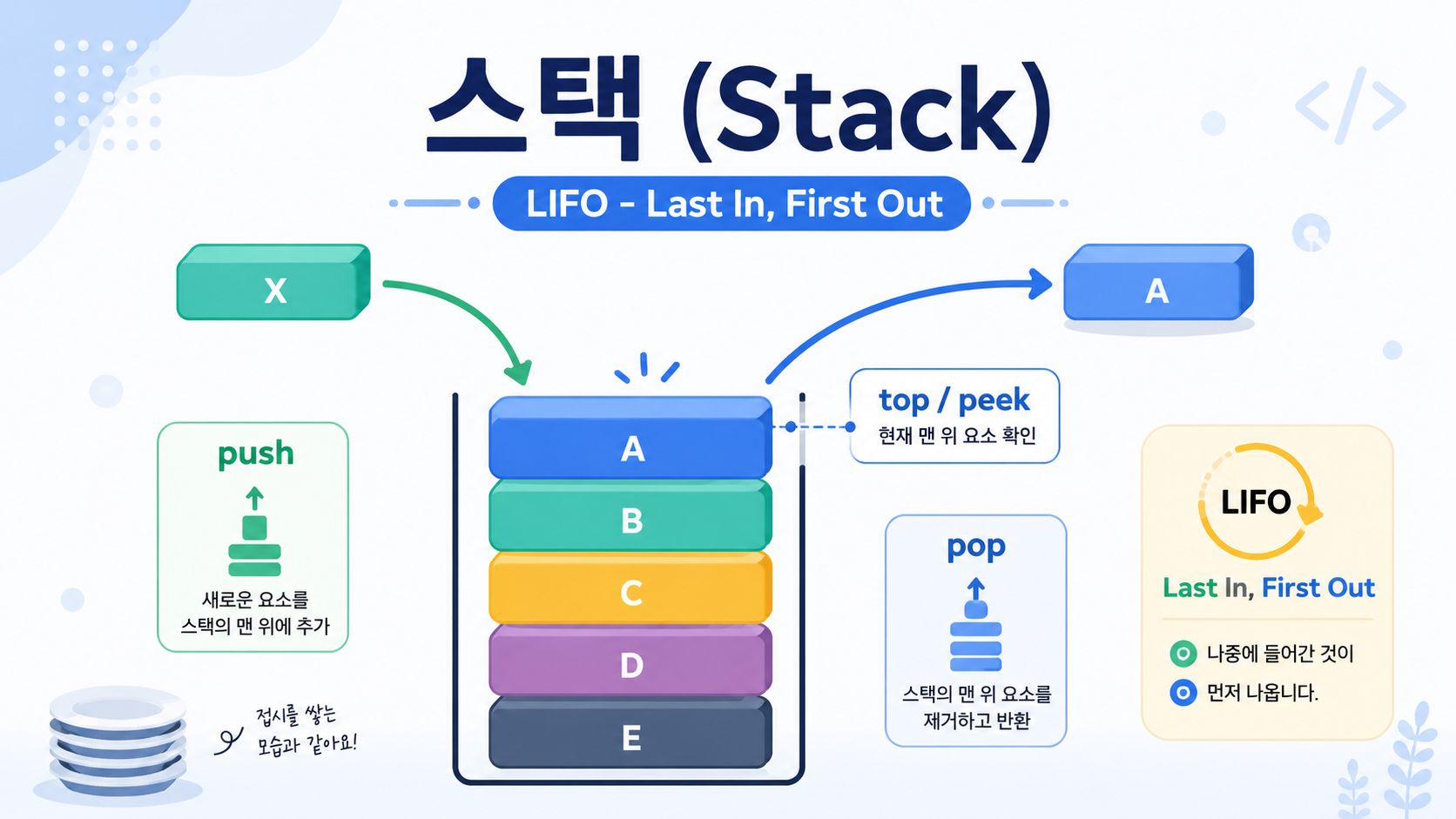
스택은 LIFO, Last In First Out 구조를 따르는 자료구조다. 즉, 마지막에 들어온 데이터가 가장 먼저 나간다.
접시를 쌓아두고 위에서부터 꺼내는 모습을 생각하면 이해하기 쉽다!
스택의 대표 연산은 데이터를 넣는 push, 가장 위의 데이터를 꺼내는 pop, 가장 위의 데이터를 확인하는 top 또는 peek이다.
스택은 함수 호출 관리, 재귀 호출, 괄호 검사, DFS, 뒤로 가기, 실행 취소 기능 등에 자주 사용된다. 특히 DFS에서는 현재 경로를 따라 깊게 탐색하다가 더 이상 갈 곳이 없으면 이전 상태로 되돌아가야 하므로 스택 구조가 잘 맞는다.
stack = []
stack.append(10)
stack.append(20)
stack.append(30)
print(stack.pop()) # 30
print(stack.pop()) # 202. 큐 Queue
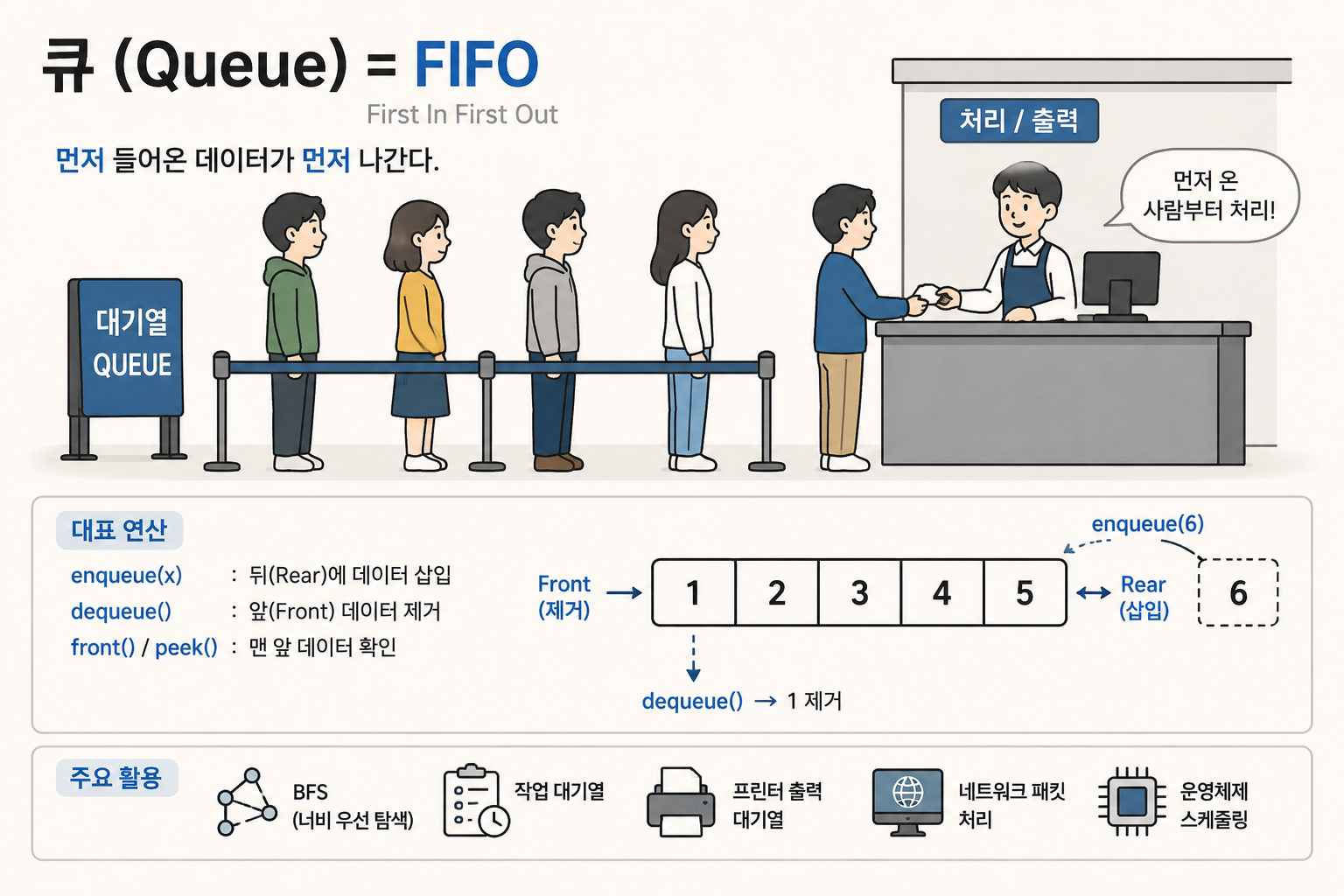
큐는 FIFO, First In First Out 구조를 따르는 자료구조다. 즉, 먼저 들어온 데이터가 먼저 나간다.
줄을 서서 기다리는 상황을 생각하면 된다. 먼저 온 사람이 먼저 처리되고, 나중에 온 사람은 뒤에서 기다린다. Java의 Queue 문서도 FIFO 큐에서는 새 원소가 큐의 뒤쪽에 삽입되고, 앞쪽 원소가 제거 대상이 된다고 설명한다.
큐의 대표 연산은 데이터를 넣는 enqueue, 데이터를 꺼내는 dequeue, 맨 앞 데이터를 확인하는 front 또는 peek이다. 큐는 BFS, 작업 대기열, 프린터 출력 대기열, 네트워크 패킷 처리, 운영체제 스케줄링 등에서 자주 사용된다.
from collections import deque
queue = deque()
queue.append(10)
queue.append(20)
queue.append(30)
print(queue.popleft()) # 10
print(queue.popleft()) # 203. 덱 Deque

덱은 Double-Ended Queue의 줄임말로, 양쪽 끝에서 삽입과 삭제가 모두 가능한 자료구조다. 일반 큐는 뒤에서 넣고 앞에서 빼는 구조지만, 덱은 앞에서도 넣고 뒤에서도 넣을 수 있으며, 앞에서도 빼고 뒤에서도 뺄 수 있다. Java의 Deque 문서도 덱을 양쪽 끝에서 삽입과 제거를 지원하는 선형 컬렉션이라고 설명한다.
from collections import deque
dq = deque()
dq.append(10) # 오른쪽 삽입
dq.appendleft(20) # 왼쪽 삽입
dq.append(30)
print(dq) # deque([20, 10, 30])
print(dq.popleft()) # 20
print(dq.pop()) # 304. 힙 Heap

힙은 최댓값 또는 최솟값을 빠르게 찾기 위한 자료구조다. 일반적으로 완전 이진 트리 형태로 설명되며, 부모와 자식 사이에 일정한 우선순위 관계를 유지한다. 최소 힙에서는 부모 노드의 값이 자식 노드의 값보다 작거나 같고, 최대 힙에서는 부모 노드의 값이 자식 노드의 값보다 크거나 같다.
힙은 우선순위 큐를 구현할 때 많이 사용된다. 우선순위 큐는 먼저 들어온 순서가 아니라, 우선순위가 높은 데이터가 먼저 나오는 구조다. 예를 들어 응급실 환자 처리, 작업 스케줄링, 다익스트라 알고리즘, 최소 비용 문제 등에서 사용된다.
import heapq
heap = []
heapq.heappush(heap, 5)
heapq.heappush(heap, 1)
heapq.heappush(heap, 3)
print(heapq.heappop(heap)) # 1
print(heapq.heappop(heap)) # 35. 해시 Hash / 해시 테이블 Hash Table

해시는 임의의 데이터를 고정된 범위의 값으로 변환하는 방식이다. 자료구조 관점에서는 보통 해시 테이블을 의미하는 경우가 많다. 해시 테이블은 키를 해시 함수에 넣어 배열의 인덱스처럼 사용하고, 이를 통해 데이터를 빠르게 저장하거나 조회한다.
대표적인 예시는 Python의 dict, Java의 HashMap, C++의 unordered_map이다.
다만 해시 테이블이 항상 O(1)인 것은 아니다. 해시 충돌이 많이 발생하거나, 테이블이 너무 꽉 차거나, 해시 함수가 좋지 않으면 성능이 저하될 수 있다. 그래서 해시 테이블은 보통 load factor, rehashing, collision resolution 같은 개념과 함께 이해해야 한다. Java HashMap 문서도 capacity, load factor, rehashing이 성능에 영향을 준다고 설명한다.
student = {}
student["name"] = "Kim"
student["score"] = 95
print(student["name"]) # Kim
print(student["score"]) # 956. 집합 Set
집합은 중복을 허용하지 않는 자료구조다. 수학의 집합처럼 원소의 존재 여부가 중요하고, 같은 값은 한 번만 저장된다. Python 공식 문서는 set을 중복되지 않는 hashable 객체들의 순서 없는 컬렉션이라고 설명하며, 멤버십 테스트, 중복 제거, 합집합·교집합·차집합 같은 연산에 사용된다고 설명한다.
집합은 내부적으로 해시 기반으로 구현되는 경우가 많다. 예를 들어 Java의 HashSet은 Set 인터페이스를 구현하며, 내부적으로 해시 테이블, 실제로는 HashMap 인스턴스에 의해 뒷받침된다고 설명한다. 또한 해시 함수가 원소를 적절히 분산한다는 가정하에 add, remove, contains, size 같은 기본 연산이 상수 시간 성능을 제공한다고 설명한다.
s = set()
s.add(10)
s.add(20)
s.add(10)
print(s) # {10, 20}
print(10 in s) # True
print(30 in s) # False집합은 중복 제거, 방문 여부 체크, 빠른 존재 확인, 공통 원소 찾기, 차집합 계산 등에 자주 사용된다. 정리하면, 집합은 중복 없이 원소를 저장하고, 특정 값이 존재하는지 빠르게 확인해야 할 때 사용한다.

N, M = map(int, input().split())
paper = []
for i in range(N):
line = input().split()
paper.append(line)
result = []
for j in range(M):
check = set()
for i in range(N):
check.add(paper[i][j])
if len(check) == 1:
for x in check:
result.append(x)
else:
result.append("??")
for i in range(M):
print(result[i], end=" ")
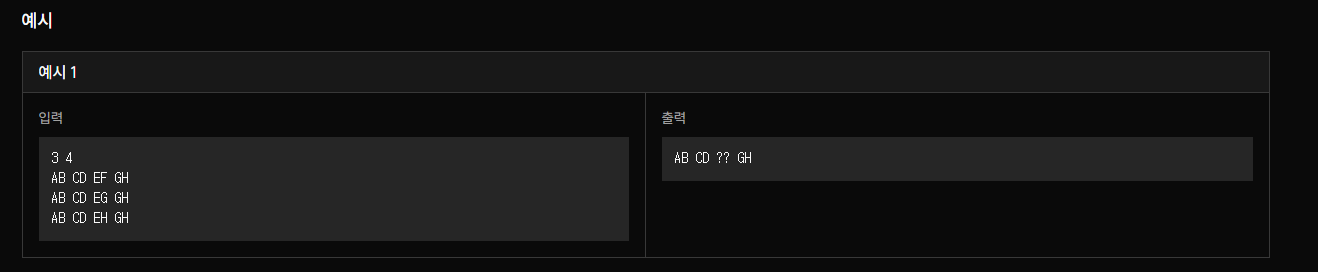
n, m을 사용해서 얼마 정도의 크기에 넣을 것 인지 확인을 하고.
line이라는 변수를 사용하여서 실제로 그 값들을 넣는다.
paper = [
["AB", "CD", "EF", "GH"],
["AB", "CD", "EG", "GH"],
["AB", "CD", "EH", "GH"]
]
그 후 set이라는 python에서 주는 자료구조를 활용하여서 for문을 활용해서 check.add를 해준다.
그러면
paper에 있는 값들을 비교하면서 AB, AB, AB가 같으면 하나만 check으로 들어가고 값이 다르면 check에 EF, EG, EH이렇게 들어간다. 그러면 자료구조 특성상 모두 다 같은 값이 들어가면 len이 1, 그것이 아니라면 len이 1보다 크게 된다. 이것을통해서 문제를 풀었다.
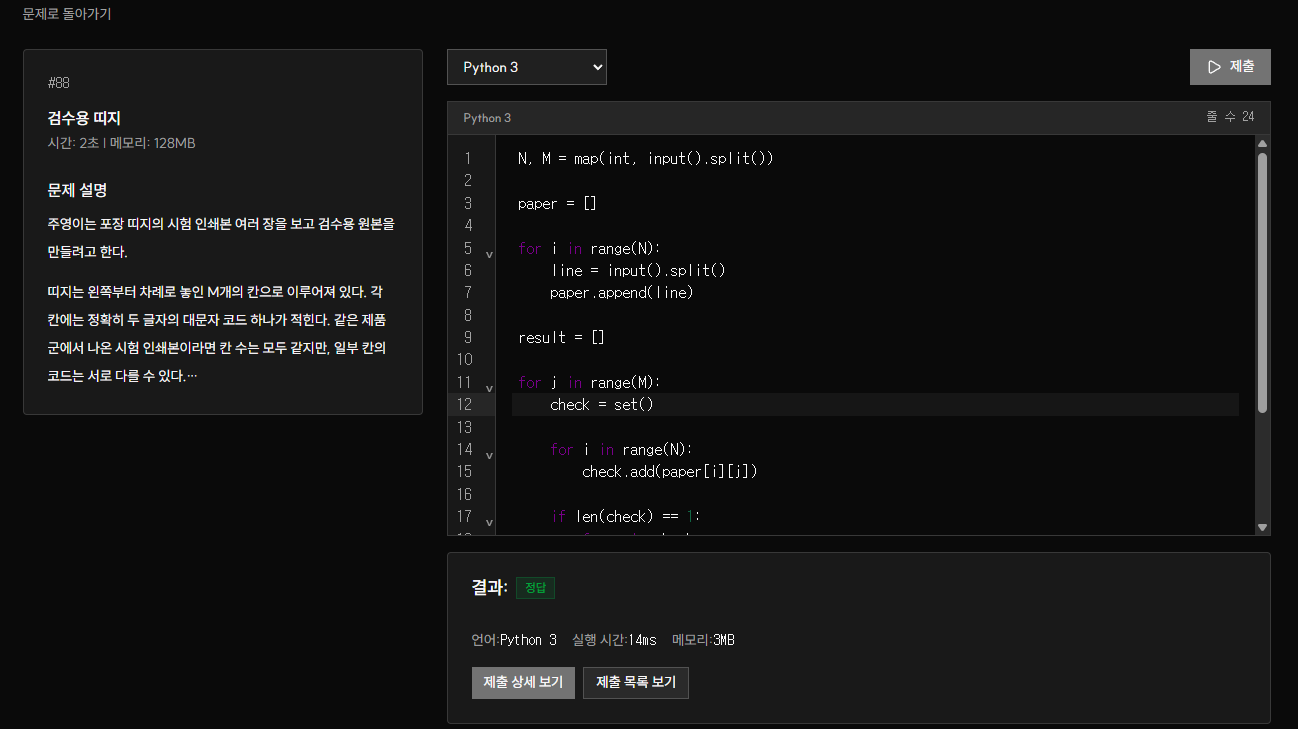


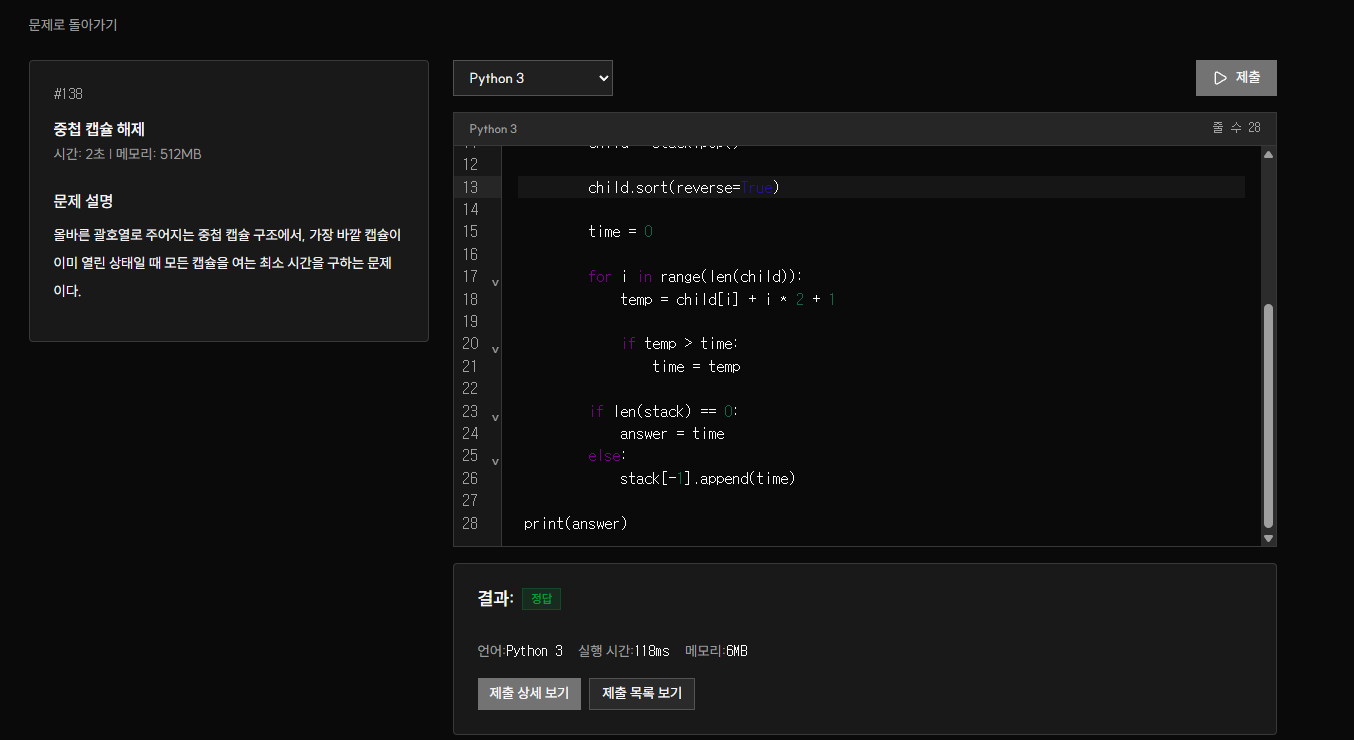
#138 중첩 캡슐 해제 | 리수 온라인 저지
정답 1회 / 제출 3회. 올바른 괄호열로 주어지는 중첩 캡슐 구조에서, 가장 바깥 캡슐이 이미 열린 상태일 때 모든 캡슐을 여는 최소 시간을 구하는 문제이다.
loj.kr
해당 문제는 stack 구조를 이해하려고 문제를 선택했다. 해당 문제는
1. 첫 번째 입력에서는 N을 입력받아서 캡슐의 개수를 확인한다.
2. 그 다음 입력되는 괄호 문자열을 보고, (가 나오면 새로운 캡슐이 시작된 것으로 보고 )가 나오면 하나의 캡슐이 끝난 것으로 본다.
3. 각 캡슐 안에 있는 내부 캡슐들을 어떤 순서로 열어야 전체 시간이 가장 적게 걸리는지 계산해서, 모든 캡슐을 여는 데 필요한 최소 시간을 출력하는 문제이다.
N = int(input())
S = input().strip()
stack = []
answer = 0
for ch in S:
if ch == '(':
stack.append([])
else:
child = stack.pop()
child.sort(reverse=True)
time = 0
for i in range(len(child)):
temp = child[i] + i * 2 + 1
if temp > time:
time = temp
if len(stack) == 0:
answer = time
else:
stack[-1].append(time)
print(answer)
N을 사용해서 괄호 문자열이 얼마 정도의 크기인지 확인을 하고, S라는 변수를 사용하여서 실제 괄호 문자열을 입력받는다.
그 후 stack이라는 리스트를 사용해서 캡슐 구조를 저장한다.
문자열을 왼쪽부터 하나씩 확인하면서 여는 괄호 '('가 나오면 새로운 캡슐이 시작된 것이기 때문에 stack에 빈 리스트를 넣어준다.
이런 식으로 새로운 캡슐 공간을 만들어주는 것이다.
그 다음 닫는 괄호 ')'가 나오면, 지금 보고 있던 캡슐 하나가 끝났다는 뜻이므로 stack에서 pop을 사용해서 꺼낸다.
-> 여기까지가 if else문을 나눈 이유!
그 후, 꺼낸 값은 그 캡슐 안에 들어있던 자식 캡슐들의 시간이 된다. (이해가 잘 가지 않아서)예를 들어 어떤 캡슐 안에 자식 캡슐들이 3개 있고, 각각 걸리는 시간이 4, 2, 1이라고 하면
child = [4, 2, 1]
이런 식으로 저장되어 있다.
그 후 child.sort(reverse=True)를 사용해서 오래 걸리는 캡슐부터 먼저 열도록 정렬해준다.
-> 그 이유는 오래 걸리는 캡슐을 먼저 열어야 전체 시간이 줄어들기 때문이다.
그 다음 for문을 사용해서 각각의 자식 캡슐을 여는 데 걸리는 시간을 계산한다.
temp = child[i] + i * 2 + 1
여기서 child[i]는 그 자식 캡슐 내부를 전부 여는 데 걸리는 시간이고, i * 2 + 1은 그 자식 캡슐까지 이동해서 여는 데 걸리는 시간이다. 이 값들 중에서 가장 큰 값이 현재 캡슐을 전부 여는 데 필요한 시간이 된다. 계산이 끝난 후에 아직 stack에 부모 캡슐이 남아있으면, 방금 계산한 시간을 부모 캡슐의 리스트에 넣어준다.
stack[-1].append(time)
만약 stack이 비어있다면, 지금 계산한 캡슐이 가장 바깥쪽 캡슐이라는 뜻이므로 answer에 저장한다. 마지막으로 answer를 출력하면 전체 캡슐을 여는 데 걸리는 최소 시간이 나온다.
결과적으로, 이 문제는 괄호를 하나씩 보면서 stack에 캡슐 구조를 저장하고, 닫는 괄호가 나올 때마다 해당 캡슐의 시간을 계산하는 방식으로 풀었다.


'프론티어' 카테고리의 다른 글
| 프론티어_AFL 코드 분석 (0) | 2026.05.26 |
|---|---|
| 프론티어_fuzzing_101 환경 설정 (0) | 2026.05.18 |
| 프론티어_CodeQL실습 (0) | 2026.05.13 |
| 프론티어_CodeQL. (0) | 2026.05.13 |
| 프론티어_IDS/IPS에 대해서 (0) | 2026.05.13 |



